Learning from the Pros
Basilio Noris
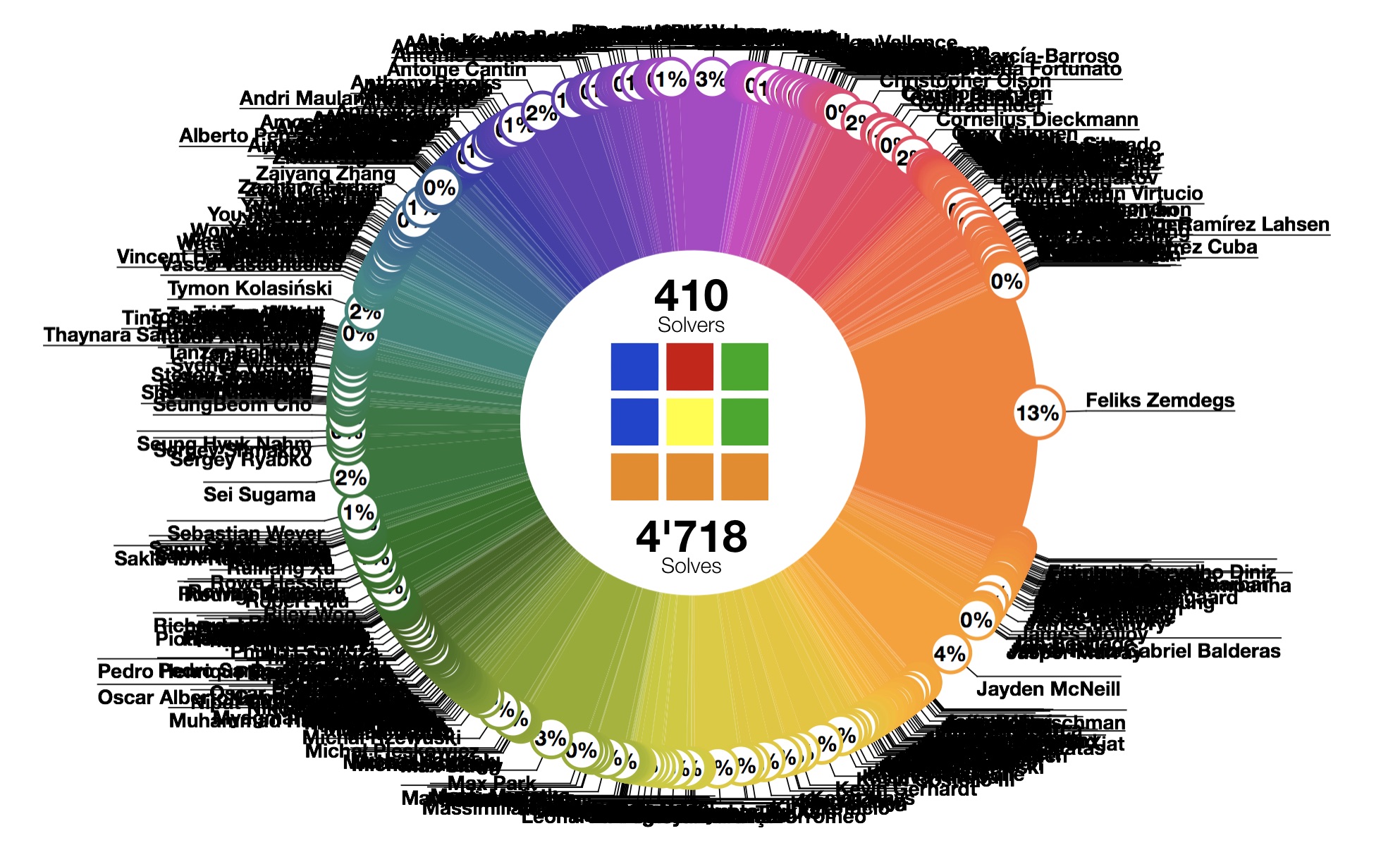
In this multi-part series of articles we will dig into this data to see what we can learn from the fastest solvers and their fastest solves.
What data can tell us about solving the cube efficiently and fast
Solving the cube as a craft has evolved over the past 40 years and as people have studied and trained to solve it ever faster, a body of knowledge has started to take shape. The past 10 years have seen the time necessary to solve the cube plunge to a handful of seconds, while the amount of know-how has skyrocketed. A body of data has started to form, as databases of algorithms, but also reconstructions of eminent solves have been gathered into repositories for the cubing community. Foremost among these, www.speedcubedb.com now comprises thousands of algorithms for many puzzles and events, and several thousands of solves by the fastest cubers in the world.
It is hard to overstate the amount of work behind this data
This work, and this article would not have seen light were it
not for the herculean work of a number of people in the cubing
community, it is worth mentioning 3 of them. Heading the solve
reconstruction effort, Stuart Clark not only
reconstructs the vast majority of all new solves, to the tune of
hundreds of solves per month, but he manages and nudges
the main efforts of the reconstruction community. The
torchbearer mantle was passed onto him by the original
reconstruction god, Brest, who single-handedly
reconned half of the four thousands solves available at the time
of this writing. Closing this holy triumvirate is Gil
Zussman, who not only created, designed and coded speedcubedb.com
and cubedb.net
(both formidable feats of technological craftiness) but
developed a plethora of tools for solve reconstruction, alg
discovery and management, that make the life of speedcubers the
world over so much easier and better.
And finally thanks to Anto, Ben, Feliks and Phillip for going
over a pre-read of this and for their insightful feedback.
And with that out of the way, let's see what we found out in the data
You can't be super-fast AND super-efficient
At some point, higher TPS is only possible at the cost of
efficiency
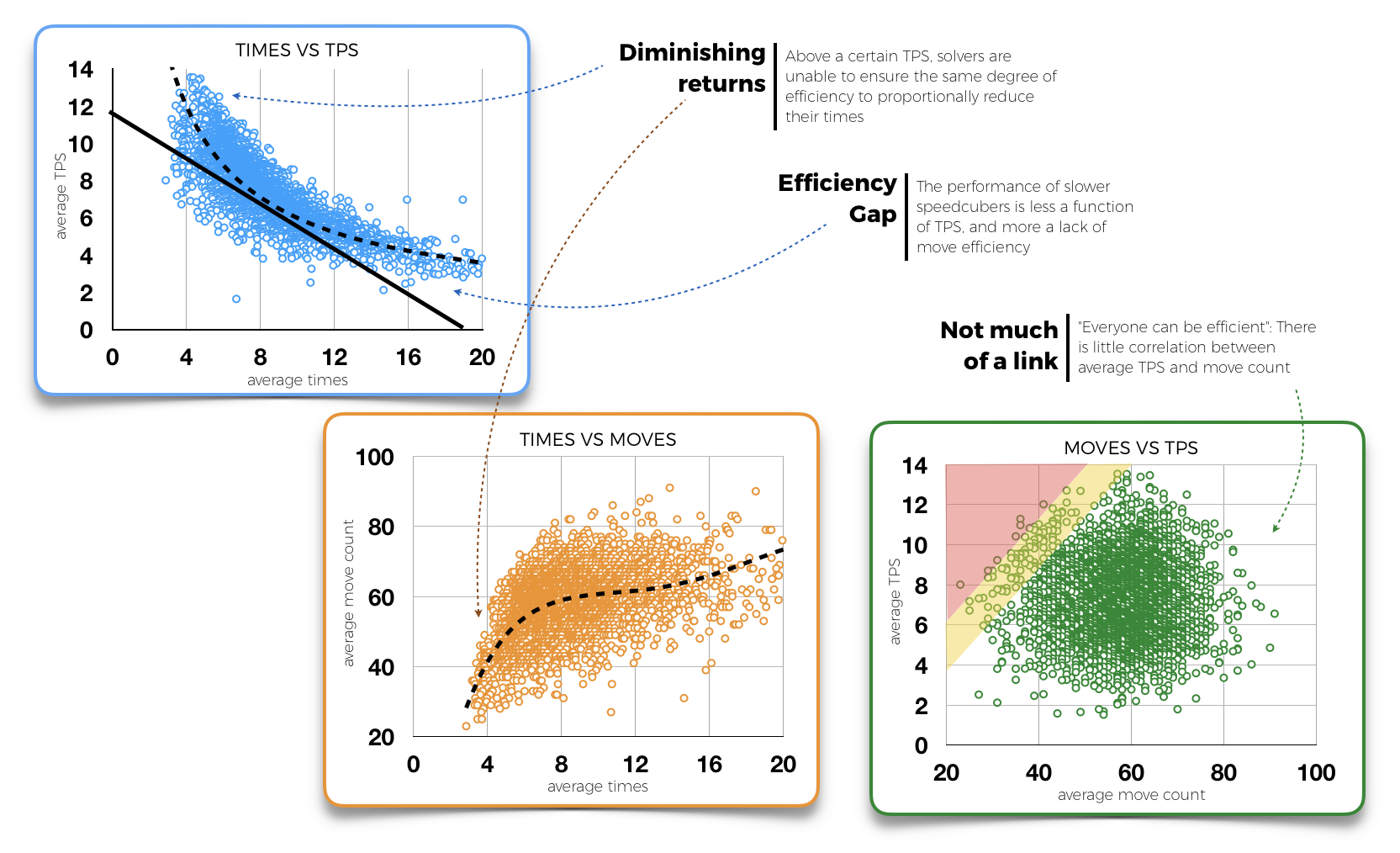 When we combine the solve time
with the turns per second (TPS) of the solver, and the number of
moves to solve the cube, we're struck by two things: While there
is a relatively linear relationship between times and TPS until we
hit about 8 seconds, the times hit a wall even though very-high
TPS can still happen. Conversely, while the average number of
moves per solve decreases slowly until about the same time, it
takes a sharp downward turn for the faster solves. So far so good.
However, when we look at solve moves vs TPS we realise that there
are very few solves that have both very low moves and very high
tps, whereas there are many more that have only one of them. This
suggests that – for the time being – it is not really possible to
find efficient solutions while going very fast.
When we combine the solve time
with the turns per second (TPS) of the solver, and the number of
moves to solve the cube, we're struck by two things: While there
is a relatively linear relationship between times and TPS until we
hit about 8 seconds, the times hit a wall even though very-high
TPS can still happen. Conversely, while the average number of
moves per solve decreases slowly until about the same time, it
takes a sharp downward turn for the faster solves. So far so good.
However, when we look at solve moves vs TPS we realise that there
are very few solves that have both very low moves and very high
tps, whereas there are many more that have only one of them. This
suggests that – for the time being – it is not really possible to
find efficient solutions while going very fast.Roteto rotato, more complex move-set or more rotations?
Fueling the fire of the high-gen vs rotate debate
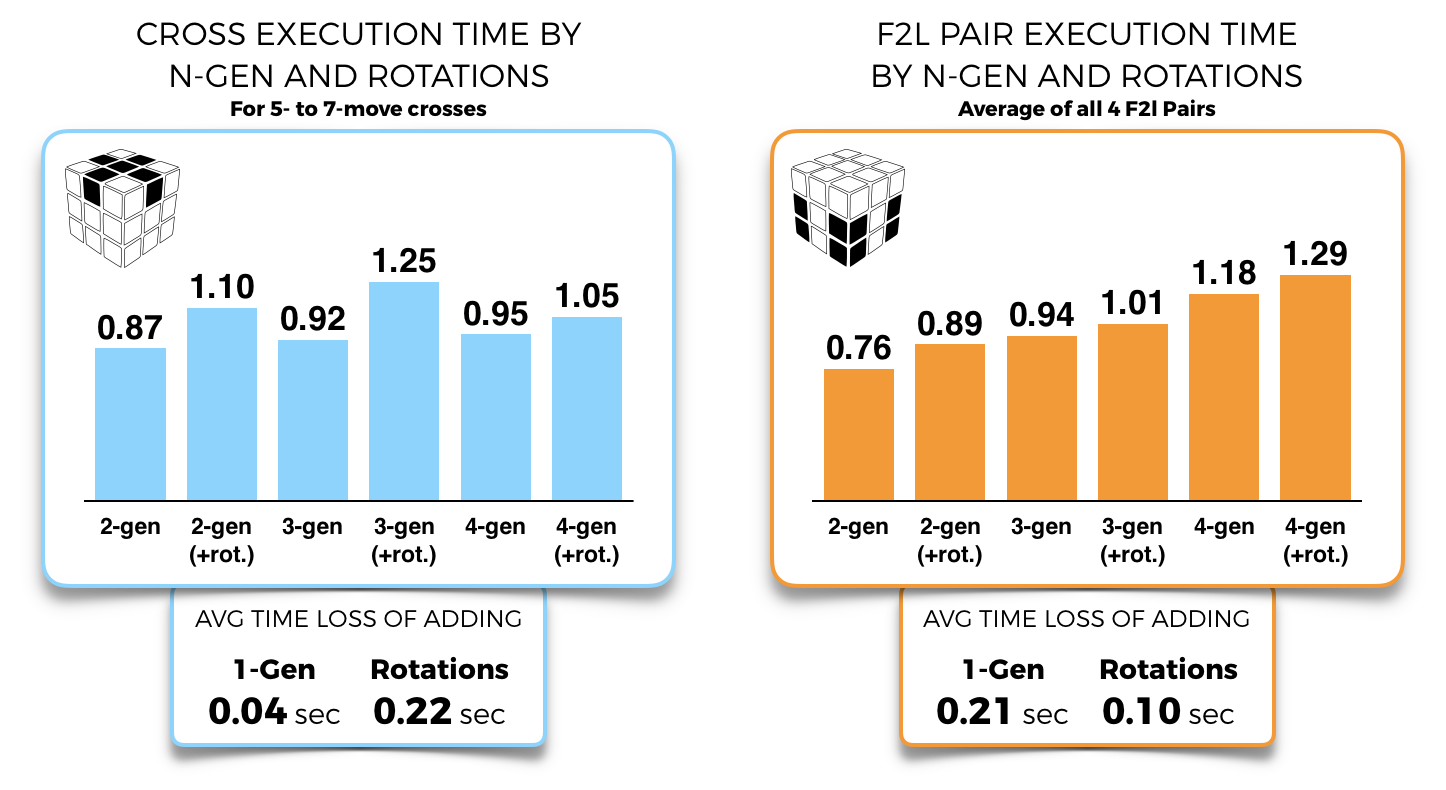
The opposite is true for f2l, where the much higher tps (2/3 faster than cross tps on average) means that spamming low-gen moves whilst incurring rotations is a successful strategy, regardless of whether we move from 2-gen to 3 or from 3 to 4.
The desire for no-rotation methods (which made sense when fingetricks were vastly more limited by cube hardware, and TPS was by necessity much lower) might not be that relevant anymore.
Solve pairs in the back first, and don't get too fancy with
your inserts
BR slot for first pair is the most frequent go-to option for
the fastest solves
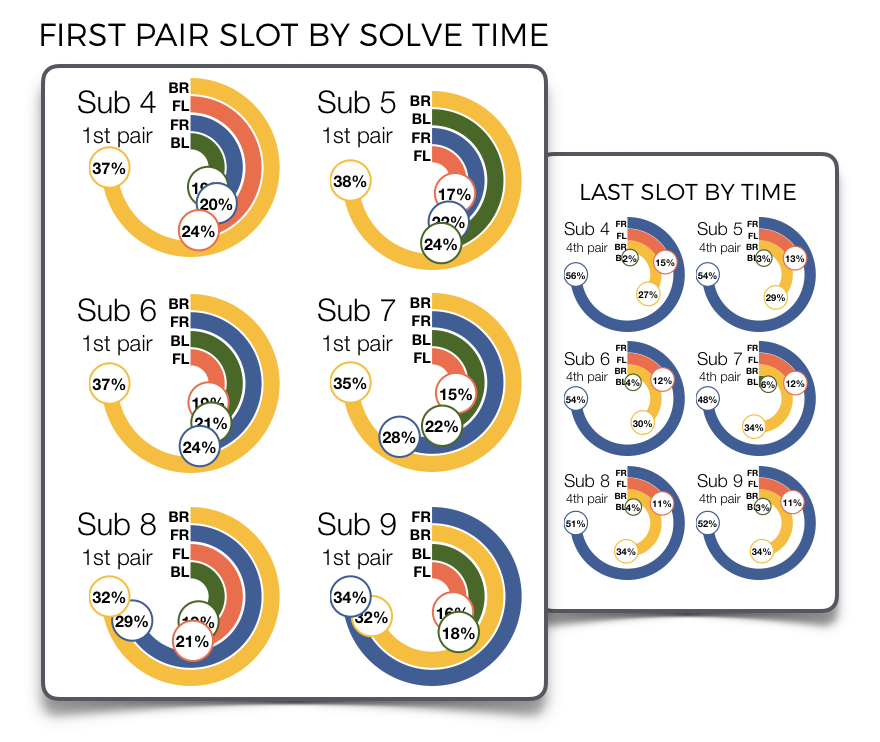
The vast majority of inserts are very vanilla
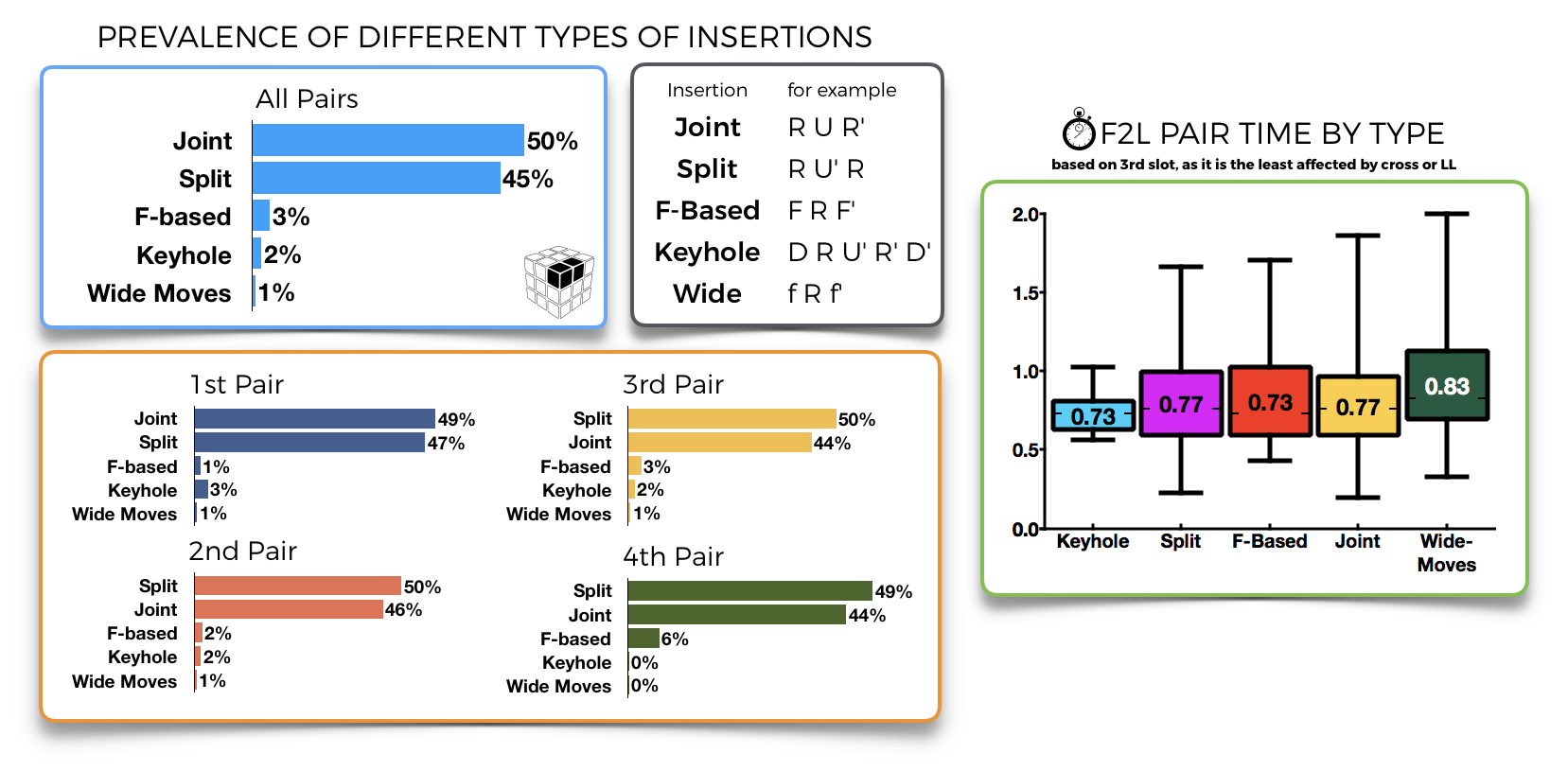
95% of pair insertions use standard RU/LU insertions, foregoing the more complex FRUF or wide-move insertions (slice-move inserts didn't even make the graph, but you can find them below). This has some validity – wide-move insertions are slower than the others – but not only, as F-based ones are just as fast if not slightly faster, than vanilla. They're just not used much.
Keyhole (the fastest insert on average) is very rare, and appears mostly for the first couple of pairs, while edge-controlling F inserts (e.g. sledge) appear mostly (and unsurprisingly) for last pair.
S pls, or actually don't. Save it for OLL
The zoomer excitement for S moves everywhere might be a bit premature
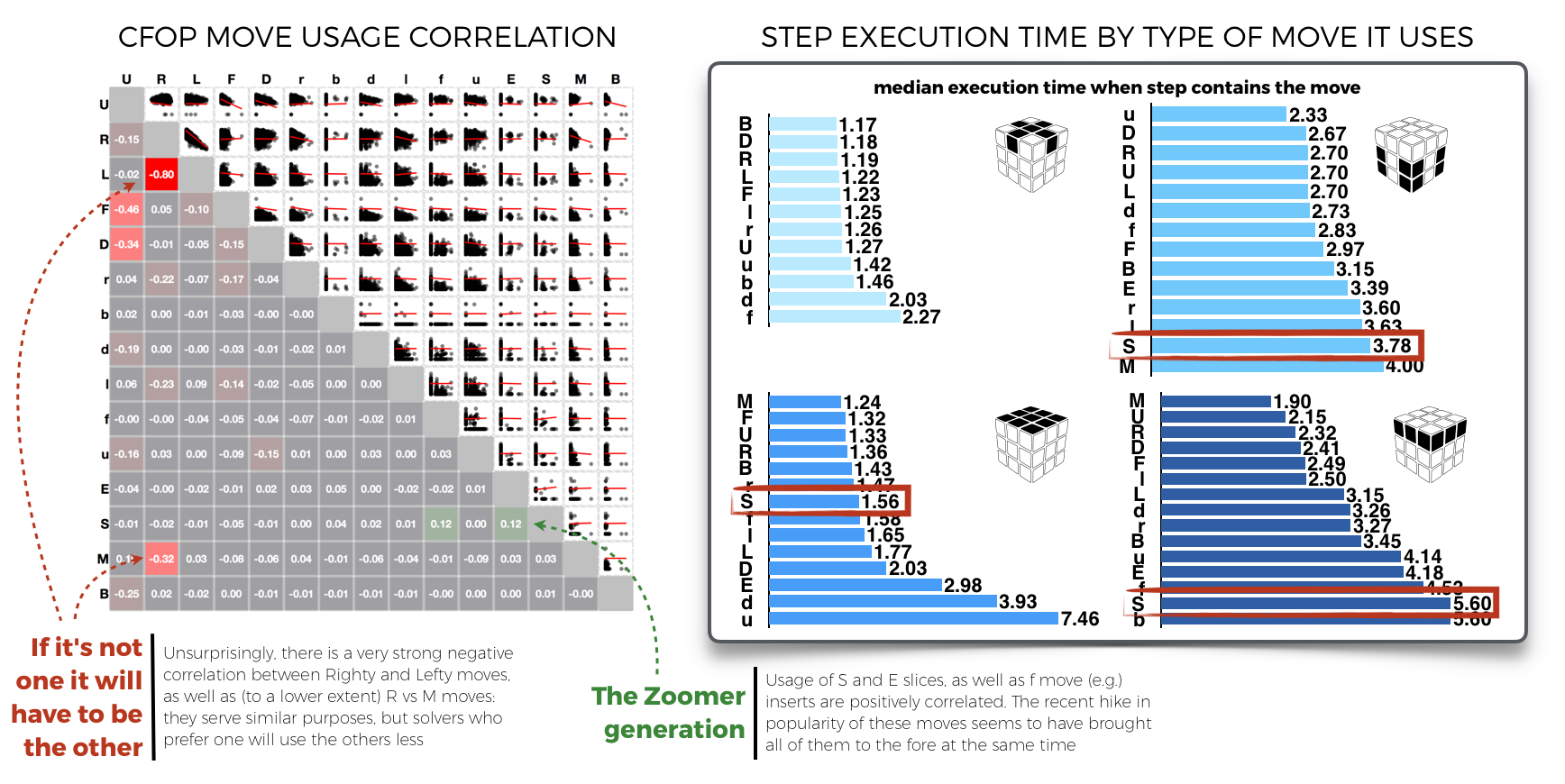 The
relatively recent improvements in cube hardware technology, have
made the execution of non-M slice viable during solves, and their
usage has gain some traction, especially in the younger community.
Whilst we know that M slices have their place in a solve (the
fastest OLL and PLL algs demonstrate this easily), the same is not
clear for S and E slices. When solvers utilise them in any step
except OLL, those steps will be significantly slower than when
using their outer-layer variant.
The
relatively recent improvements in cube hardware technology, have
made the execution of non-M slice viable during solves, and their
usage has gain some traction, especially in the younger community.
Whilst we know that M slices have their place in a solve (the
fastest OLL and PLL algs demonstrate this easily), the same is not
clear for S and E slices. When solvers utilise them in any step
except OLL, those steps will be significantly slower than when
using their outer-layer variant.With that being said, our data reflects the performance of current top-level solvers, who have learned their ropes in an earlier less slice-heavy era. It might be that with time the advantages given by these "new" moves (previously less viable due to hardware limitations) might come to the fore. However, the fact that S moves have quickly found their place in OLL but not in others indicates that if they presented a stark improvement on alternative moves those might have come to light already. The prominence of "simple works better" instances especially in f2l would suggest slices might not be the way to go for at least some of the cfop phases.
Nope, dot-OLLs are just fine
While the exec time of dot OLLs is slightly longer, any
attempt to avoid them is worse
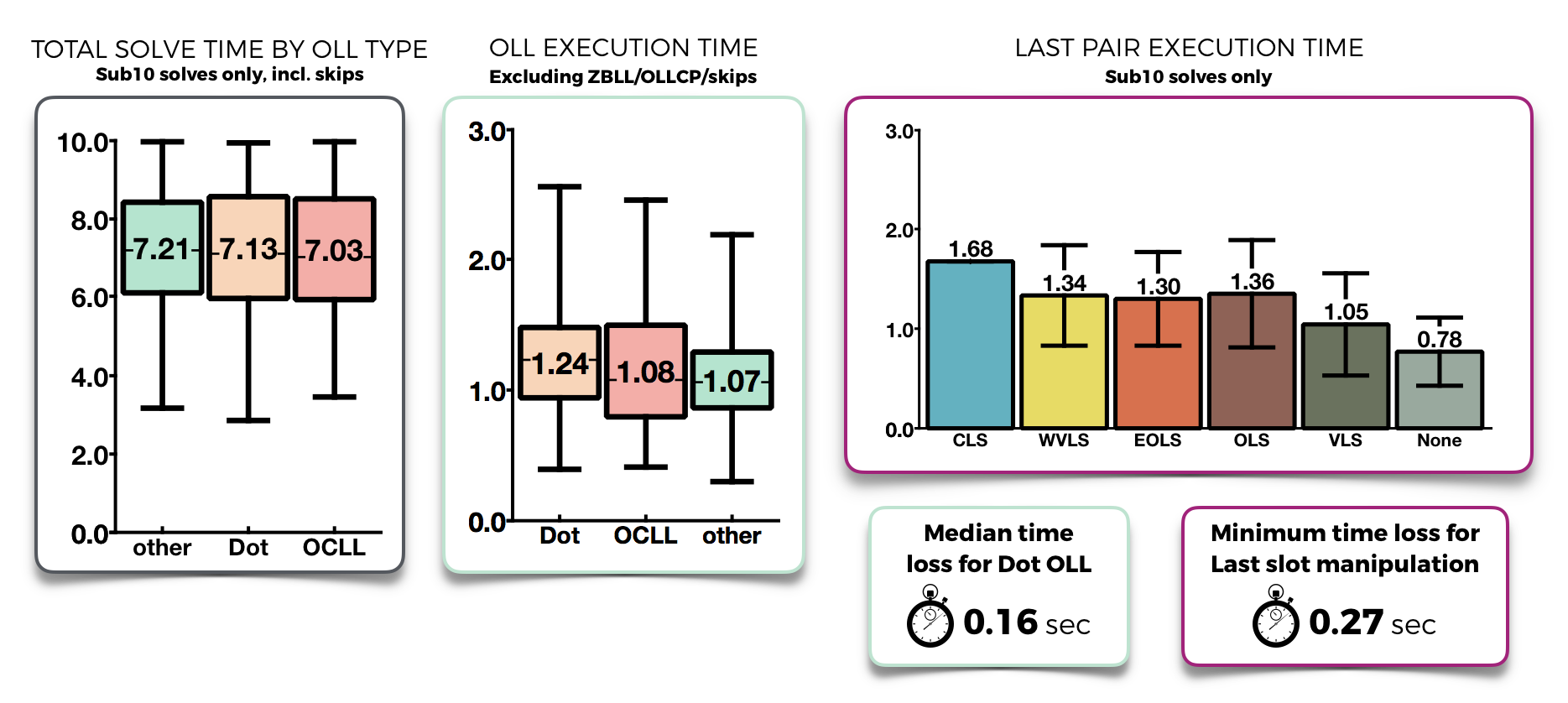 Oll executions require a rather wide
range of time in general, but it true that the median execution
for Dot OLLs is slightly slower than other OLLs (by about
0.16sec). This doesn't seem to affect solves overall: the median
solve containing a Dot OLL sits evenly in-between solves with OCLL
and those with other cases. What's more, any attempt to influence
EO through last slot will lose you more time than the expected
gain in time. So just learn good algs, and don't worry about dot
OLLs.
Oll executions require a rather wide
range of time in general, but it true that the median execution
for Dot OLLs is slightly slower than other OLLs (by about
0.16sec). This doesn't seem to affect solves overall: the median
solve containing a Dot OLL sits evenly in-between solves with OCLL
and those with other cases. What's more, any attempt to influence
EO through last slot will lose you more time than the expected
gain in time. So just learn good algs, and don't worry about dot
OLLs.What about XCrosses, AUFs, PLLs, Skips?
There's plenty more, too much to put onto a single article. If
you're looking for more, check out the whole analysis. You can find it here.Understandably most of our efforts have been dedicated to analyzing CFOP solves for now. However Stewy and his minions have been churning out reconstructions for other methods (Roux chief among them, but others as well!) which will be the focus of our coming work.
Some caveats on the data:
By construction this data is selecting mainly great solves from top-level cubers. This means that luck plays a role (especially in the fastest solves), otherwise the solve would simply not be part of this data. A better approach would be to conduct solver-specific analysis and normalize by the solver median times, but this will require much more data on individual solvers (right now we have only a handful of people with more than 50 solves each). We're working towards this ; ).Basilio Noris is an expert in machine learning with a passion for cubing, data visualization and astrophotography. He did his academic research on the early diagnosis of Autism, bridging psychology, neurology and data science. He now runs a company doing analysis of human behavior in retail and manufacturing environments.